😊 오늘은 최근 AI 업계에서 주목받고 있는 'VFM'에 대해 알아보고자 합니다.
그런데 파운데이션모델이 AI의 뼈대 역할을 하는 아주 큰 규모의 AI 모델로써 이를 기본으로 챗봇, 번역기, 문서요약 등 다양한 영역에 활용할 수 있다는 것은 알고 있는데 앞에 비전(Vision)이 들어간 파운데이션 모델은 도대체 무엇을 말하는 것일까요?
📜 VFM(비전 파운데이션 모델)이란?
VFM, 즉 비전 파운데이션 모델(Vision Foundation Model)은 눈으로 보는 AI에요.
즉, 기존에 우리가 알던 ChatGPT, Gemini, Perplexity 등의 AI가 문자 기반의 AI라면, VFM은 시각 기반의 AI라고 할 수 있는 것입니다.
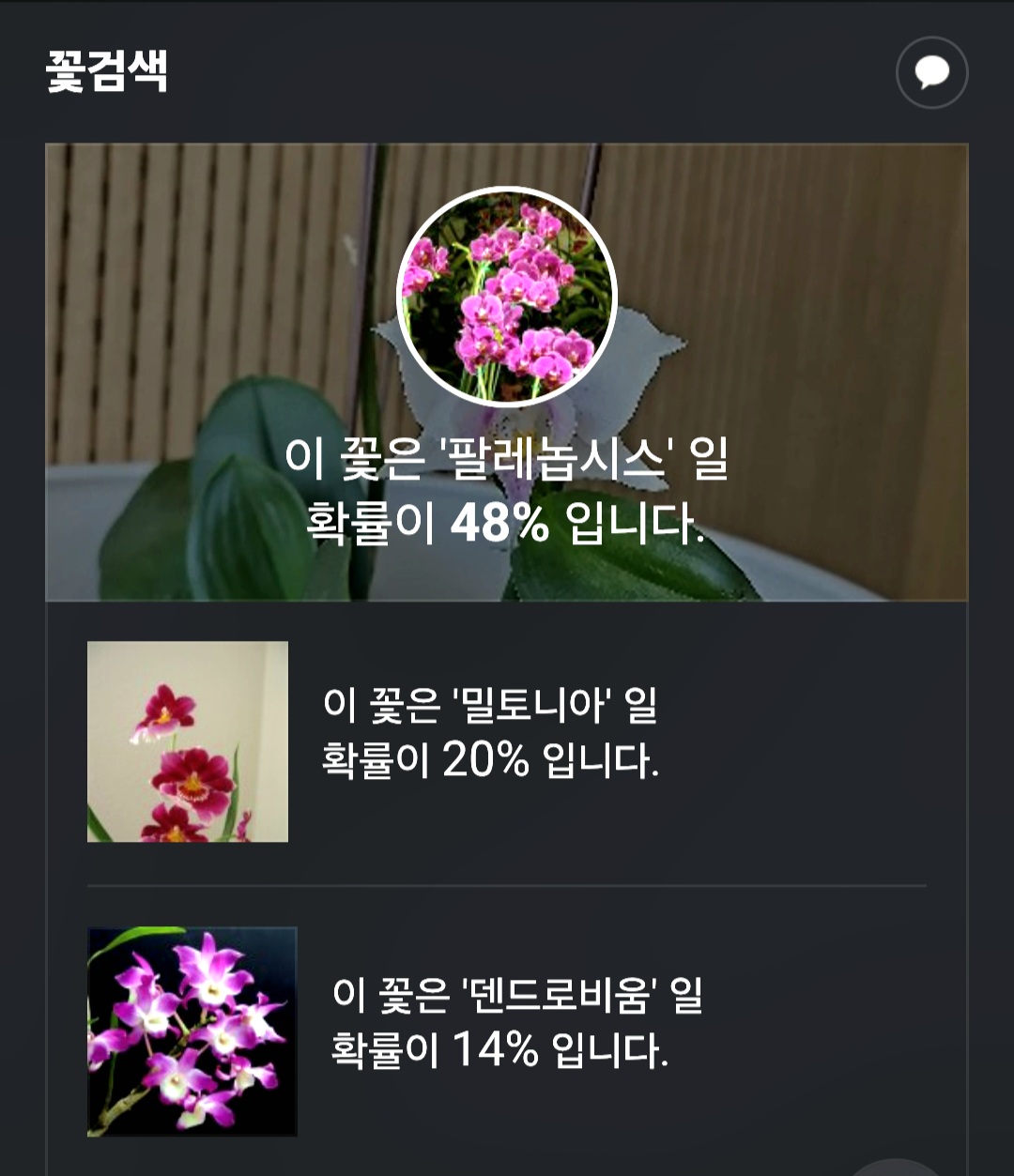
예를 든다면 D포털에서 서비스하고 있는 '꽃검색' 서비스를 들 수 있습니다.
길을 가다 이름모를 아름다운 꽃을 보고 D포털을 열어 꽃검색으로 해당 꽃을 찍으면 '이 꽃은 00꽃일 확율이 00%입니다'라는 검색 결과를 보여주는 꽃검색, 사용해보신 경험이 있으시죠?
이 꽃검색의 경우 꽃을 확인하는데 특화된 AI로 볼 수 있습니다.
수많은 꽃의 이미지를 등록시켜 학습하고, 핸드폰으로 어떠한 꽃을 찍어 물어보면 학습한 꽃의 이미지를 추론하여 확률적인 정확도를 제시해 주는 것이지요.
이렇듯 이전에는 특정 이미지만 분류하거나, 특정 물체만 찾아내는 AI가 따로 따로 만들어졌지만, 이제는 하나의 대형 모델이 사진 분류, 물체 찾기, 이미지 설명 등 거의 모든 시각 인식 작업을 한 번에 할 수 있게 된것이지요.
이러한 AI 모델이 바로 VFM, 비전파운데이션모델이랍니다.
예를 들어, VFM에 강아지 사진을 보여주면 강아지의 품종을 맞추는 것은 물론이고 강아지가 있는 장소, 강아지의 현재 활동과 모습 등에 대해 사람이 직접 눈으로 보는 것처럼 자세히 설명을 해주게 됩니다.

💡 VFM의 주요 특징은?
그렇다면 이러한 VFM의 주요 특징은 무었일까요?
이전의 AI가 글로써 명령을 주고 받고, 문서를 인식했다면 VFM은 글 이외에도 이미지, 사진 등 다양한 방식의 매개체를 통해 명령을 내릴 수 있어 사용이 훨씬 용이하다는 것입니다.
또한 어떤 VFM은 세부 원리는 모르겠지만 제로샷(Zero-Shot)능력을 보유하고 있어 미리 학습하지 않은 사물, 동물에 대해서도 추론을 할 수 있다고 하니 정말 신기할 따름입니다.
이러한 특징을 보유한 VFM이 가장 유용하게 사용될 분야는 바로 산업현장입니다.
조립 현장에서 여러 다른 모양의 볼트, 너트 등 부속품을 인식해내고, 로봇에 장착되어 현장을 관리하는 등 VFM이 산업현장에 활용된다면 무궁무진한 기능을 수행해 낼 수 있는거죠.
🆚 VFM과 일반 파운데이션 모델의 비교
지금까지 설명드린 VFM과 일반 파운데이션모델과의 차이를 한눈에 알아보실 수 있도록 아래의 표를 준비했습니다.
< VFM (비전 파운데이션 모델)과 일반 파운데이션 모델 (텍스트 FM 등) 비교 >
| 주요 데이터 | 이미지/비전 | 주로 텍스트 |
| 적용 분야 | 사진 분류, 탐지, 분할 등 다양한 비전 작업 | 텍스트 생성, 감정분석, 요약 등 |
| 프롬프트 방식 | 사진, 클릭, 텍스트 등 멀티모달 | 주로 텍스트 |
| 대표 예시 | SAM, DINO, CLIP, SEEM | GPT-4, Claude, Lama 등 |
간략히 정리한다면 VFM은 이미지 데이터를 기반으로 하는 AI, 기존의 파운데이션 모델은 문자 데이터 기반의 AI로 정리할 수 있습니다.
즉, VFM은 이미지로 명령하고 이미지를 인식하는 AI라 말할 수 있습니다.
텍스트 파운데이션 모델이 "글 잘 쓰는 AI"라면, VFM은 "사진 잘 보는 AI"라고도 할 수 있는 거고요.
그렇다면 이 두 AI를 사람으로 비유한다면 기존 파운데이션 모델은 작가, VFM은 화가라 할 수 있을까요?ㅎㅎㅎ
지금까지 VFM(비전 파운데이션 모델)에 대해 알아봤습니다.
개인적인 여건으로 포스팅이 쉽지 않습니다만,
처음의 열정으로 열심히 공부하겠습니다.
대한민국 국민의 1인 1AI를 기원합니다.
하단은 영어 버전입니다.
----------------------------------------------------------
😊 Today, I want to explore 'VFM,' which has recently been gaining attention in the AI industry.
I understand that foundation models are very large-scale AI models that act as the backbone of AI and can be used as a basis for various fields such as chatbots, translators, and document summarization. But what exactly does a foundation model with "Vision" in front of it mean?
📜 What is Vision Foundation Model?
VFM, or Vision Foundation Model, is an AI that essentially sees with its eyes.
While AIs like ChatGPT, Gemini, and Perplexity that we are familiar with are text-based, VFM can be considered vision-based AI.
For example, the "Flower Search" service offered by D Portal is a good illustration. If you see a beautiful flower on the street whose name you don’t know, you can open the D Portal app and use Flower Search by taking a photo of the flower. The service then shows a search result like "This flower is likely to be a 00 flower with a 00% probability."
This Flower Search is a specialized AI designed specifically for identifying flowers. It is trained on numerous flower images, and when you take a photo of a flower with your phone and ask the AI, it infers the flower based on the learned images and provides a probabilistic accuracy of its identification.
Previously, separate AIs were developed to classify specific images or detect particular objects. However, now a single large model can perform almost all visual recognition tasks at once, such as photo classification, object detection, and image captioning.
For example, if you show a dog photo to a Vision Foundation Model, it not only identifies the dog's breed but also provides detailed descriptions about the dog's location, its current activity, and appearance, just like a human would see with their own eyes.
💡 What are the key features of VFM?
So, what are the main features of VFM?
While previous AIs communicated and recognized documents mainly through text commands, VFM allows commands through various media such as images and photos, making it much easier to use.
Additionally, some VFMs possess a mysterious zero-shot ability, meaning they can infer about objects or animals they were never explicitly trained on, which is truly astonishing.
The most practical application of VFMs is in industrial settings. For example, they can recognize various shapes of bolts, nuts, and other parts on assembly lines, be mounted on robots to manage the site, and perform countless functions, making them immensely valuable in industrial environments.
🆚 Comparison Between VFM and General Foundation Models
Here is a table to help you understand the differences between VFM and general foundation models at a glance:
| Main Data | Image/Vision | Mainly Text |
| Application Areas | Various vision tasks such as image classification, detection, segmentation | Text generation, sentiment analysis, summarization |
| Prompt Types | Multimodal: images, clicks, text | Mainly Text |
| Representative Examples | SAM, DINO, CLIP, SEEM | GPT-4, Claude, Lama, etc. |
In short, VFM is an AI based on image data, while traditional foundation models are AI based on text data.
In other words, VFM is AI that both commands and recognizes images. If a text foundation model is an "AI that writes well," then VFM can be described as an "AI that sees photos well."
If we were to compare these two types of AI to people, the traditional foundation model might be a writer, and VFM could be a painter.
So far, we have explored VFM (Vision Foundation Model).
Due to personal circumstances, posting regularly is difficult, but I will continue studying hard with the same passion as before.
'AI를 알아가다' 카테고리의 다른 글
| 🎬 영상생성의 강자, 클링AI(Kling AI) 알아보기 (20) | 2025.07.21 |
|---|---|
| ⚡ AI 대격돌(AI Showdown) : Grok, Gemini, Perplexity, ChatGPT 비교 (18) | 2025.07.16 |
| 🤖 AI 모델에서 말하는 파라미터(parameter)란 무엇일까요?(The Role of Parameters in AI and Machine (15) | 2025.07.10 |
| ☁️ 실시간 날씨 질문에 답하는 AI, 그 뒤의 LLM과 RAG 이야기(AI that answers real-time weather questions: The story behind LLM and RAG) 🤖 (28) | 2025.07.01 |
| 🏞️ AI로 이미지 생성하기 실습(지휘하는 햄스터) (38) | 2025.06.18 |